Prototyp zum Clustering musealer Sammlungsdaten veröffentlicht
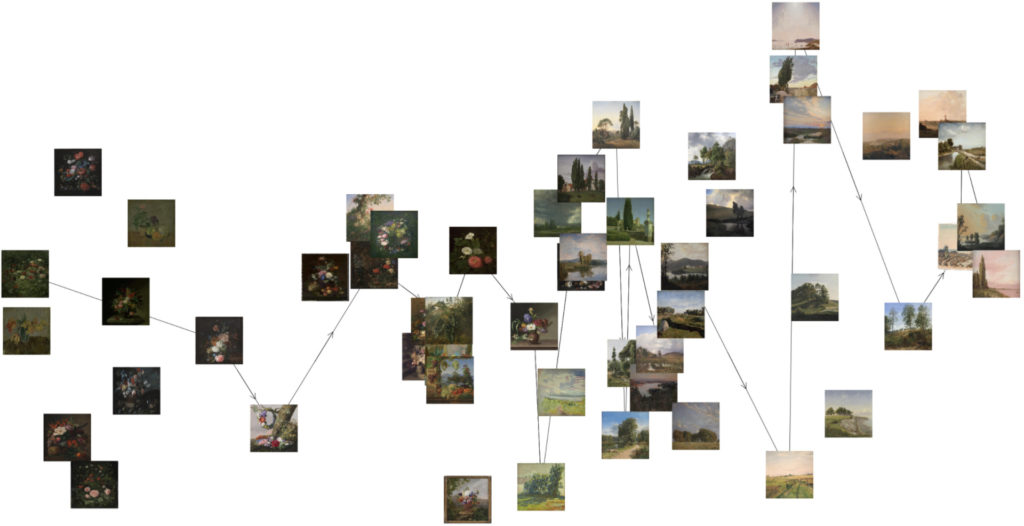
Scatterplot des Pfades durch den hochdimensionalen Raum von einem Kunstwerk zu einem anderen mit einer durch Pfeile illustrierten Wegrichtung (Bilder: Statens Museum for Kunst, Kopenhagen, gemeinfrei)
Der erste Prototyp im Forschungsprojekt »Training the Archive« ist veröffentlicht. Mit diesem wird es möglich, einClustering von Bilddaten aus einer musealen Sammlung vorzunehmen, um interessante visuelle Zusammenhänge zwischen den Kunstwerken zu erkennen. Anschließend soll der Mensch als Expert*innen wieder eingebunden werden, indem den verwendeten Netzwerken zur Bilderkennung das Wissen von Kurator*innen trainiert wird. Dadurch sollen die gebildeten Cluster dynamischer und personalisierter gestaltet werden.
Zum Repository mit allen Notebooks und der Anleitung geht es hier:
»Training the Archive« (2020–2023) ist ein Forschungsprojekt, das die Möglichkeiten und Risiken von KI in Bezug auf die automatisierte Strukturierung von musealen Sammlungsdaten zur Unterstützung der kuratorischen Praxis und der künstlerischen Produktion auslotet.